The pharmaceutical industry operates under immense pressures, with the development of a single new drug often consuming a decade of research and financial outlays that can soar into the millions. Data shows a staggering failure rate of over 90% for drug candidates during clinical trials, with a multitude of potential drugs never even reaching that stage. This inefficiency is predominantly attributable to safety concerns, as many compounds turn out to be toxic. As the drug development process evolves, the advent of artificial intelligence (AI) tools provides a glimmer of hope for mitigating these failures and streamlining the rigorous journey from laboratory to market.
Harnessing the Power of AI for Drug Safety Analysis
Researchers at the Broad Institute of MIT and Harvard are at the forefront of this transformation, employing AI to predict biological interactions before drugs ever confront the complexity of living organisms. Under the guidance of scholar Srijit Seal, these researchers have established advanced predictive machine learning models that sift through the intricacies of chemical structures to determine their potential toxicological effects in humans. These tools not only assess fundamental cellular health and pharmacokinetics but delve deeper into specific organ functions, notably heart and liver performance.
The implications of such predictive modeling are profound. With a suite of machine learning tools detailed in numerous academic publications, researchers can strategically narrow the focus on more viable drug candidates, reserving their limited resources for the most promising substances. What Seal and his colleagues are doing isn’t merely academic; it’s a pragmatic approach that enriches the drug discovery pipeline.
The Significance of Understanding Drug Toxicity
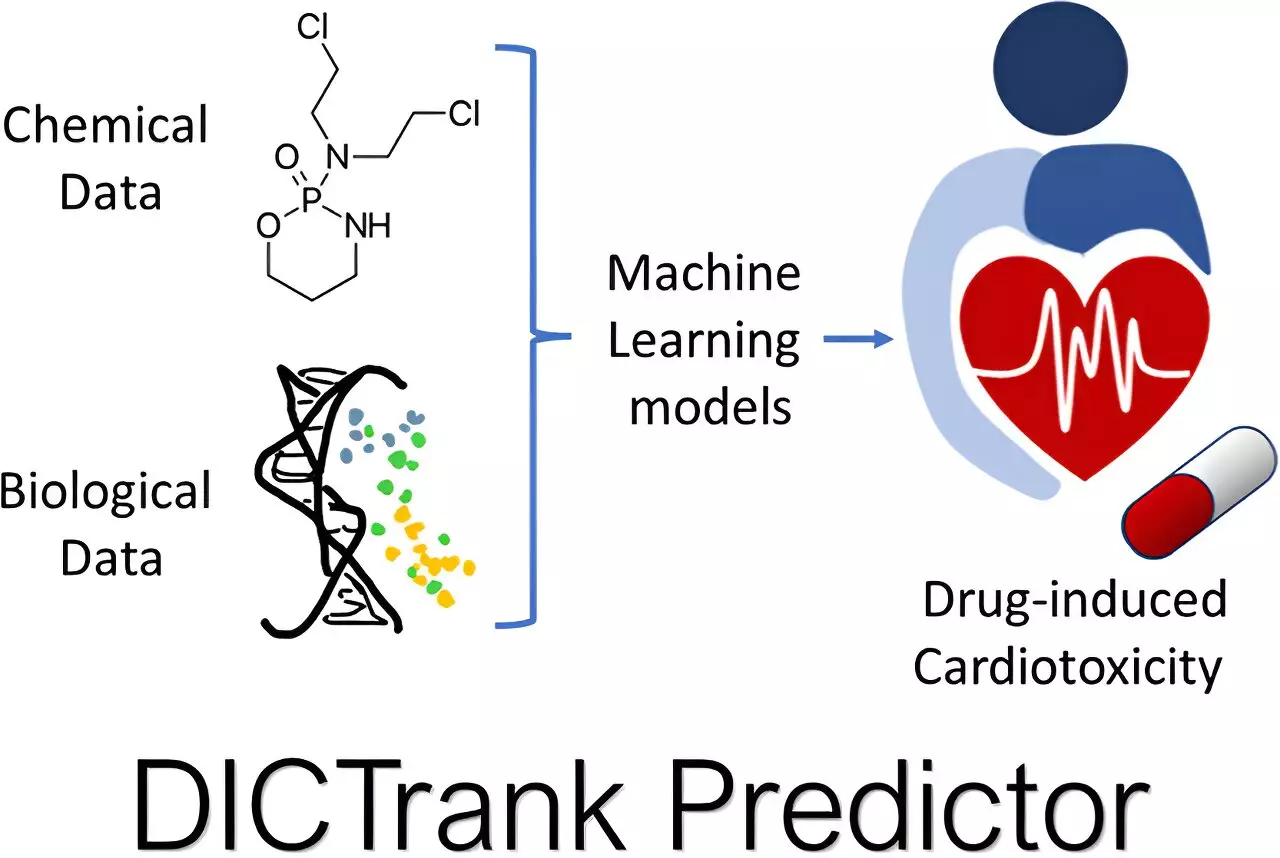
Drug toxicity remains a significant hurdle, particularly in the post-marketing phase where unsafe drugs are pulled from shelves, often due to issues like drug-induced cardiotoxicity (DICT) and drug-induced liver injury (DILI). Recognizing this risk, the FDA has compiled extensive datasets categorizing drugs based on their propensity for causing injury to vital organs. Seal and his team ingeniously harnessed these datasets to formulate toxicity predictive models—one specifically targeting cardiotoxicity and another focusing on liver damage.
This endeavor reflects a monumental shift towards data-driven decision-making in drug development. The DICTrank Predictor stands out as the first model to leverage the FDA’s categorical rankings for DICT, providing critical insights that ultimately guide safer drug design. Meanwhile, the DILIPredictor illustrates the capability to differentiate between safe and harmful compounds across different species, enhancing confidence in pre-clinical results.
Pharmacokinetics: A Necessary Cornerstone
Beyond toxicity, understanding how a drug is absorbed, distributed, metabolized, and excreted—collectively known as pharmacokinetics—is quintessential for drug efficacy. Seal aptly points out that ineffective distribution can render a drug useless, while prolonged retention in the body can precipitate adverse effects. The complexity of pharmacokinetic modeling demands sophistication; employing traditional methods is not only laborious but also costly. This is where machine learning offers a positively disruptive path forward.
Seal’s initiative to develop a pharmacokinetic predictive model alongside these toxicity models illustrates a more comprehensive approach to drug design. His sentiment that drug design requires an effective feedback mechanism resonates strongly as it underscores the need for real-world applicability—ensuring newly designed drugs function as intended without unforeseen complications.
Enhancing Toxicity Insight through Cell Health Analysis
The intricacies of drug-induced cellular toxicity require further understanding beyond mere prediction. Alongside toxicity models, there emerges a need for researchers to grasp the underlying mechanisms affecting cell health. Seal diverted his focus to tools like CellProfiler, which provides critical imaging data for evaluating cellular morphology. Yet, despite its capabilities, industry biologists often find themselves grappling with the biological meaning behind the data.
To bridge this gap, Seal’s innovative creation, BioMorph, utilizes deep learning to connect image-based morphological data to biological outcomes. By correlating cellular health parameters with imaging data, BioMorph can elucidate how particular compounds exert their effects on cell health—turning raw data into interpretable biological insights. This kind of pioneering work not only enriches scientific understanding but also enhances practical application in drug development.
A Bright Future for Drug Development
The trajectory for predictive modeling in drug discovery is undoubtedly transformative. The application of AI to predict toxicological outcomes represents a progressive leap forward, one that could potentially mitigate the staggering failures currently commonplace in drug development. As researchers like Seal push the boundaries of what machine learning can achieve, the pharmaceutical industry may soon experience a revolution—one that enhances drug safety, efficacy, and ultimately public health.