Training deep learning models effectively requires access to high-quality datasets. However, one of the critical challenges faced in this area is label noise—the inaccuracies or inconsistencies in the labels of training data, which can severely impair the model’s ability to classify data accurately during testing. This scenario is increasingly common in large-scale datasets, prompting researchers to explore innovative solutions to mitigate the effects of such noise. Among these efforts is the recent work led by a team from Yildiz Technical University, which introduces a cutting-edge algorithm designed to enhance model training in the presence of label noise.
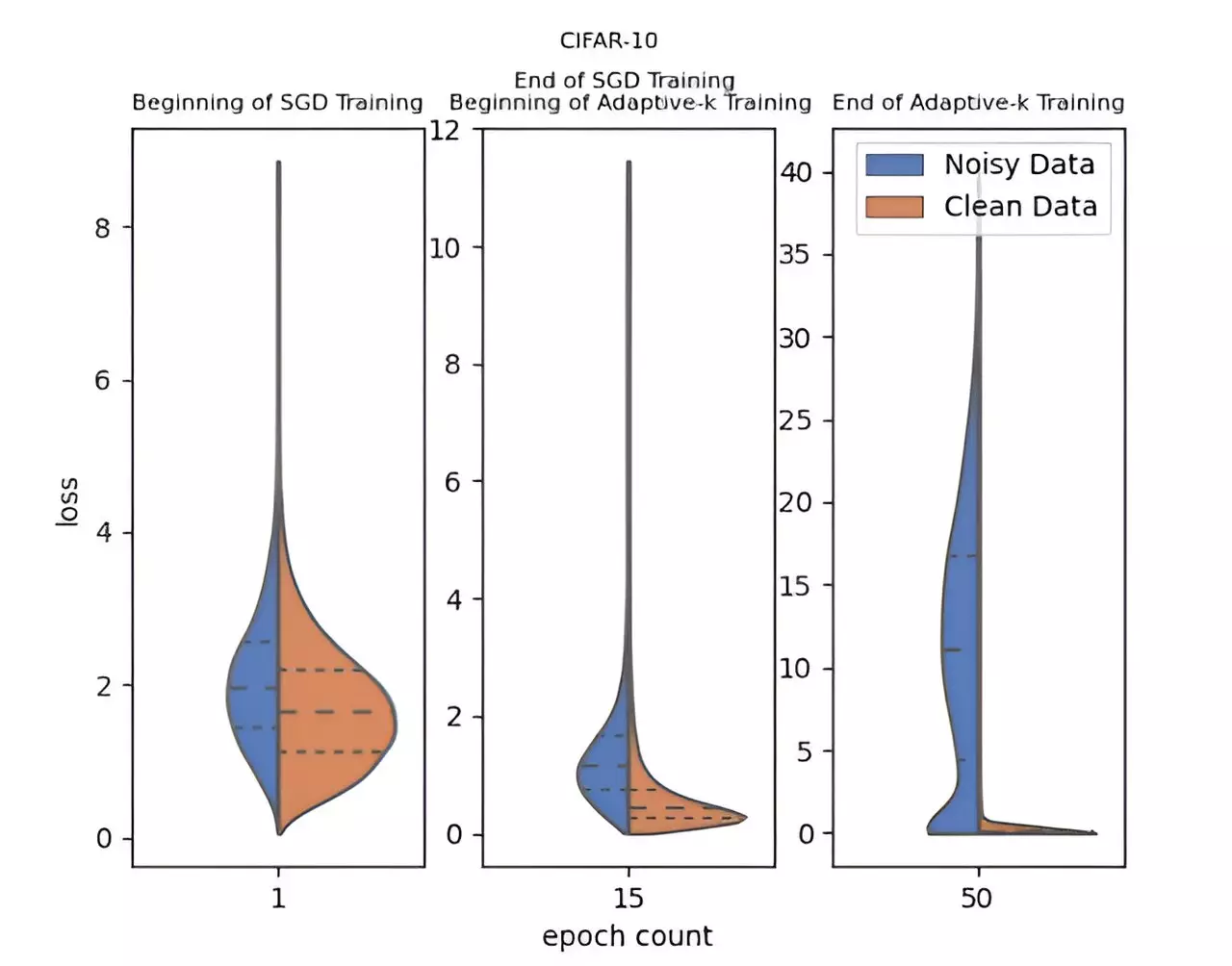
The Adaptive-k method, developed by researchers Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali, represents a significant advancement in this field. Unlike traditional approaches that often rely on predefined metrics or excessive adjustments, Adaptive-k dynamically determines the optimal number of samples extracted from mini-batches for model updates. This unique feature allows for more efficient identification and separation of noisy labels, facilitating better overall classification accuracy.
What sets Adaptive-k apart is its simplicity and ease of implementation. Notably, it does not require knowledge of the noise ratio within the dataset, nor does it necessitate any additional training processes or substantial increases in training duration. This accessibility to practitioners marks an important step forward, as it allows for immediate application without complicating the workflow.
A critical analysis conducted by the research team highlights the superior performance of Adaptive-k relative to other established algorithms, including Vanilla, MKL, and Trimloss. Their rigorous experimental setup involved testing across various datasets—spanning both images and text—to ensure robust validation of the method under different conditions.
The findings indicated that Adaptive-k consistently approached the performance seen in an ideal scenario where noisy samples are completely excluded—the so-called Oracle method. This benchmark underscores the efficiency of Adaptive-k in managing the complexities associated with noisy labels, showcasing its practical viability in real-world applications.
Contributions to the Field and Future Directions
The research team has made substantial contributions not only in creating the Adaptive-k algorithm but also in providing comprehensive theoretical analysis. Their work addresses crucial aspects like noise ratio estimation without prior dataset knowledge and evaluates comparative efficacy against existing solutions.
Looking ahead, the researchers plan to refine the Adaptive-k method further, exploring broader applications beyond its initial scope. By identifying additional optimizations and enhancements, they aim to establish Adaptive-k as a foundational approach in the realm of deep learning, particularly for noisy datasets.
The Adaptive-k method represents a significant advancement in deep learning research, providing a robust alternative to traditional approaches in handling label noise. As the field continues to expand, the implications of this work could lead to more effective model training, paving the way for advancements in various applications that rely on deep learning technology.